Popular Study Attributes Negative Reception of Star Wars: The Last Jedi to Gender and Race Changes, But The Study May Be Flawed!

A recent twitter analysis of the social media harassment surrounding Star Wars and The Last Jedi attributes negative tweets to an inherent hatred of females and minorities – through the research’s data may be flawed.
Last week, The Washington Post ran an article written by Bethany Lacina, an Associate Professor of Political Science at the University of Rochester, discussing a recent analysis she had performed of tweets surrounding the general Star Wars topic and the specific topic of Kelly Marie Tran. Kelly Marie Tran, who played Rose Tico in Star Wars: The Last Jedi, has recently spoken about her recent departure from social media platforms over harassment seemingly based on her race and gender. A New York Times piece written by Tran sparked further discussion on the role race, gender, and diversity have played in negative reactions to The Last Jedi.

BEVERLY HILLS, CA – MARCH 04: Kelly Marie Tran attends the 2018 Vanity Fair Oscar Party Hosted By Radhika Jones – Arrivals at Wallis Annenberg Center for the Performing Arts on March 4, 2018 in Beverly Hills, CA. (Photo by Presley Ann/Patrick McMullan via Getty Images)
These findings are used to support the three main arguments of Lucina’s research:
- Offensive language and hate speech have a modest but clear presence.
- Abusive posts are not due to automated accounts (bots)
- Posters use more profanity and slurs to talk about women and minorities and to talk to female fans.
Lacina’s analysis, the findings of which can be read in full on Lacina’s website, presents the following conclusions based on her research:
- Botometer estimates that about 4.4% of the results of a Twitter search for Star Wars were produced by bots.
- Tweets about Rose Tico/Kelly Marie Tran were less likely to have negative sentiment than tweets about Star Wars in general (40% versus 70%).
- Even though female fans receive more hate speech in their mentions, female podcasters received fewer tweets with negative sentiment (20% versus 36%)
- About 6% of SW/TLJ posts use offensive language. The rate of offensive language in posts about RT/KMT is double that: 12%.
- Hate speech was about 60% more common in tweets about RT/KMT compared to other Star Wars topics (1.8% versus 1.1%)
- Offensive language is 2.5 times more common (18%) in negative posts about RT/KMT.
- Hate speech is four times more common when fans complain about Star Wars’ first non-white female lead (4%) compared to when they complain about other parts of the franchise (1.2%).
- 17% of negative tweets sent to women contain offensive language, twice the rate (8.5%) in tweets to male fans.
- Hate speech is also about twice as common in a negative tweet sent to a female fan compared to a negative tweet sent to a male fan (1.4% versus 0.63%).
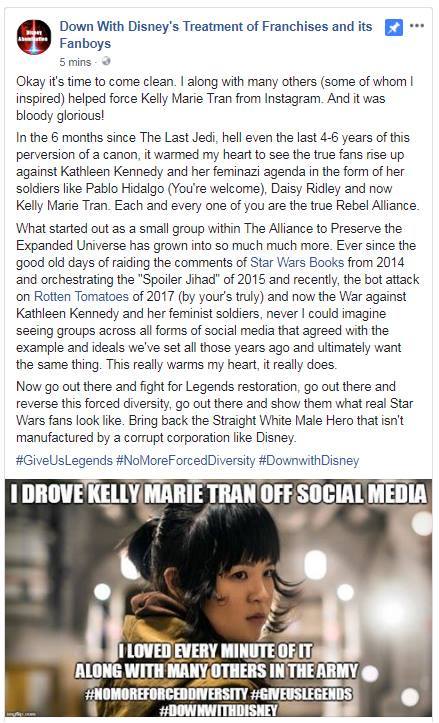
A sample of the abhorrent harassment of Kelly Marie Tran, celebrated by a disgusting, self-described harasser. This is true harassment, as opposed to rude disagreements and swear words.
These findings provide stark evidence in support of Lacina’s arguments. However, upon review of the details of Lacina’s published analysis, it is notable that many of Lacina’s research methods and information are sometimes classified arbitrarily or subjectively. These flaws in her research may call the validity of her research into question.
According to Lacina, the tweets used for analysis were obtained from Twitter’s Historical Search Premium API, in the following fashion:
“I conducted four searches for tweets in reverse chronological order from before June 2, 2018 at 1700 GMT, about when Kelly Marie Tran quit Instagram. The four batches of tweets were: (1) results of a keyword search for Star Wars (SW) or The Last Jedi (TLJ); (2) results of a keyword search for Kelly Marie Tran or Rose Tico (the name of Tran’s TLJ character); (3) mentions and replies sent to male fan podcasters; (4) mentions and replies sent to female fan podcasters.” -Bethany Lacina, September 2018
In reference to the fan accounts, Lacina explains how she chose which fan accounts to use in this study:
“Part of my article examines tweets sent to male and female fans. These tweets are “replies” to or “mentions” of fan podcast Twitter accounts. I began with the 23 podcast links on the StarWars.com community webpage. I noted show and host Twitter accounts listed on each podcast webpage. I divided host accounts into male-run and female-run. A show account is included in my female-run category if any of the hosts were female. After this process, I had 37 male-run accounts and 17 female-run accounts. I added 9 more female-run accounts from podcasts that had been recommended by Lucasfilm employees on Twitter. None of the podcasters are celebrities or Lucasfilm employees. […] All of the podcasters on my list are vulnerable to the charge of being indebted to Lucasfilm.” -Bethany Lacina, September 2018
As far as her knowledge of whether the researched individuals were male or female, Lacina shockingly only applies guess work:
“I guessed whether individuals were male or female based on their pictures and names. I excluded one account that had no picture and a sex-neutral name. Some of my guesses may be wrong. I have no information about podcasters’ gender identity, sexuality, race, heritage, religion, and so forth. I also do not know their opinions about the latest Star Wars films.” -Bethany Lacina, September 2018
Due to the fact that accounts could not specifically be determined to be male or female means that all her results should be taken with a grain of salt, as even by her own omission, she may be wrong, and thus inaccurately reporting the results (for example, a female fan account could be tweeting harassment concerning Star Wars, but Lacina may have reported that account as run by a male).
The sample size used by Lacina is the first alarm to sound. While searching for tweets, Lacina only searches for four specific terms (in her Washington Post article she claims that these searches were “(including variants and abbreviations),” but nothing regarding this was noted in her formal analysis). These four terms not only ignore the harassment received by male leads of these films, such as the onslaught of disgusting vitriol aimed at Adam Driver for his portrayal of Kylo Ren, but these searches (and Lacina’s research) clearly focus only on the issue surrounding Kelly Marie Tran, rather than Star Wars discourse as a whole.

Adam Driver, who portrayed Kylo Ren in The Last Jedi, also found himself the target of an onslaught of harassment directed towards his appearance, military service, and ethnicity.
On the topic of the number of tweets studied, Lacina does not specify how many tweets she uses for her initial study. In a section of the paper labeled Extended results on offensive language, Lacina asserts that a study of offensive language tweets conducted as a follow-up to her initial research, stating that,
“tweets [were] drawn from an extended keyword search for Star Wars/The Last Jedi (n=8000) and an extended Kelly Marie Tran/Rose Tico search (n=5427).” -Bethany Lacina, September 2018
The sample size is too small; how can 13,427 tweets (or less as used in the initial analysis) be examined to draw a conclusion about the entirety of such a colossal fan base (for reference, the Star Wars facebook group, at the time of writing, has 19,182,470 people following the page)?
The sample size for fan interaction is also highly suspect. Only 37 male run accounts and 26 female run accounts, all within the sphere of Star Wars podcasting, are used for this study. Not only are these accounts not random (as they were taken directly from the official Star Wars page, which essentially shows an endorsement of said podcast as an ‘acceptable’ affiliate), the size is too small to accurately attribute the effects of any action to a specific reason. A small sample size can inaccurately inflate percentages (fewer female accounts were studied, and thus any harassment would automatically have a bigger impact) while also failing to provide a reliable link between causation and correlation.

A sample size of 8000 tweets would barely even begin to represent the fans seen here at Star Wars Celebration Anaheim 2015, much less the entirety of Star Wars worldwide active on social media.
Lacina’s standards for measuring offensive language, hate speech, and harassment also seem somewhat arbitrary and subjective.
Lacina defines offensive language in her analysis as “Offensive language is profanity.“ Offensive language, usually qualified as the use of any profanity, is now being associated with hate, despite the fact that a vast majority of people routinely and regularly include swear words in their daily vocabulary (unfortunately, though Lacina does state that “offensive but complimentary” tweets do not count as harassment, she does not specify in her research whether any tweets were improperly labeled nor how they were sorted). Such a broad definition can also be used to inflate the number of friendly tweets reported as harassment and vice versa.
Lacina cites her use of technology based crawlers to interpret and appraise the level of offense and hate in any given tweet, specifically the HateSonar tool to find offensive language, an SDL Program developed by Thomas Davidson and co-authors to find hate speech, and the VADER-Sentiment-Analysis to assign a sentiment score to each tweet. While each tool is professional and certified, Lacina herself mentions that the results generated by these tools is not always entirely accurate, such as a machine’s ability to detect intent or context.
These tools also have a very large range of terms that qualify as hate speech, including terms that are frequently used in complimentary or neutral manners, such as “queer,” “retarded,” “pussy,” “ghetto,” and even “teapot.” While Lacina thankfully does state that she “read all of the tweets coded as hate speech and deleted obvious false positive[s]” one does wonder how much of her own bias was present in deciding which tweets were hateful and which were not, and how this potential bias affected the results.
Interestingly, the analysis also cites two instances of harassment that Lacina believes renders the tweets involved as invalid for her study. The first, is that “some replies and mentions sent to a fan account contain strong language but are intended to compliment or agree with the account owner.” If a tweet agrees with the original poster, then it is safe to assume that it was not counted for the study. Not only could this potentially delete a large amount of the sample size, but it also brings into question if tweets that agree or engage with an original poster simply to throw insults at a different demographic?
The second distinction made by Lacina is that of “flame wars.” By her definition, a flame war is when “people receive strongly worded responses to strongly worded tweets,” and when this occurs the interaction does not qualify as harassment. This skews the data, as it disregards original posters who may begin harassment or trolling by being the original poster of an inflammatory thread (if one were to disregard responses but count original tweets, it may make the data more accurate).

AUSTIN, TX – MARCH 12: Rian Johnson speaks onstage at the Journey to Star Wars panel during SXSW at Austin Convention Center on March 12, 2018 in Austin, Texas. (Photo by Nicola Gell/Getty Images for SXSW)
Perhaps the most troubling bit of information included in Lacina’s research is the definition of harassment as utilized within the findings. According to Lacina,
“When is a Twitter reply or mention harassment? The tweet should, at minimum, be adversarial toward the account targeted and use disproportionately hostile rhetoric compared to the target.” -Bethany Lacina, September 2018
Hostile rhetoric is not specifically defined: is the threshold merely disagreeing with someone, being rude to someone, or full blown harassment and targeted attacks? For contrast, Merriam-Webster defines harassment, which involves an element of repetition, as the following:
“b (1) : to annoy persistently (2) : to create an unpleasant or hostile situation for especially by uninvited and unwelcome verbal or physical conduct”
While Lacina’s definition is somewhat closer to the second dictionary definition, it is still too broad and raises questions on the criteria with which Lacina rates tweets and uses them in her study, thus calling the accuracy of the analysis once again into question.
Another point of consideration in the ongoing discourse surrounding Star Wars is the considerable amount of hostility from professionals in Hollywood and other nerd-related industries towards fans. Taking into consideration Lacina’s points, what would be the role of constantly insulting, berating, judging, and disregarding of people with genuine criticisms and negative feelings towards The Last Jedi in harassment? If original posters have their tweets and all negative replies disregarded for the course of this analysis, it seems an unfair slant that people who feel insulted or disagree with these actors, directors, and writers, are accused of starting unwarranted harassment, ignoring that many are responding to these pointed, negative takes.
Online harassment and attacks are becoming more and more frequent, and while Lacina’s efforts to catalog and analyze online harassment in the Star Wars fandom is noble and important for wider discussions on online culture, the research methods, information, and sometimes confusing criteria of Lacina’s analysis call the observable results of the analysis into question.
It is extremely important to research and study how online harassment works, who are the targets, and how communities can unite to fight harassment, but it is important that such studies are done properly as to make the findings and subsequent debates based on truth, rather than perception, in an effort to help speak honestly about harassment and identifying it’s actual perpetrators instead of painting large swaths of the Star Wars fandom as toxic.
More About:Comic Culture Movies